Mapping Jane Jacobs
I used optical character recognition to convert a pdf into text, named entity recognition algorithm to parse the text for places, Google Maps’ geocoding API to pull latitude / longitude coordinates and Carto to map everything. All of code is available here.
A quick overview of my steps…
Find the pdf

Convert pdf to text
Parse text for locations
Use the geotext library to extract country and cities from the text.
from geotext import GeoText
places = GeoText(s)
Look below at a few of the cities found using this tool. Clearly, there are some mistakes (Mary and Nelson are names, not places) but some cities are correctly identified (Chicago, Philadelphia). Let’s ignore this problem for now and come back to it later.
places.cities[:10]
[u'YORK',
u'Mary',
u'Nelson',
u'Kent',
u'Most',
u'Of',
u'Chicago',
u'Chicago',
u'York',
u'Philadelphia']
Use Google Maps API to pull lat/lon coordinates
coords = {}
for city in places.cities:
geocode_result = gmaps.geocode(city)
# if google maps request doesn't return any data, don't do anything
if len(geocode_result) == 0:
pass
else:
lat = geocode_result[0]['geometry']['location']['lat']
lon = geocode_result[0]['geometry']['location']['lng']
coords[city] = ((lat,lon))
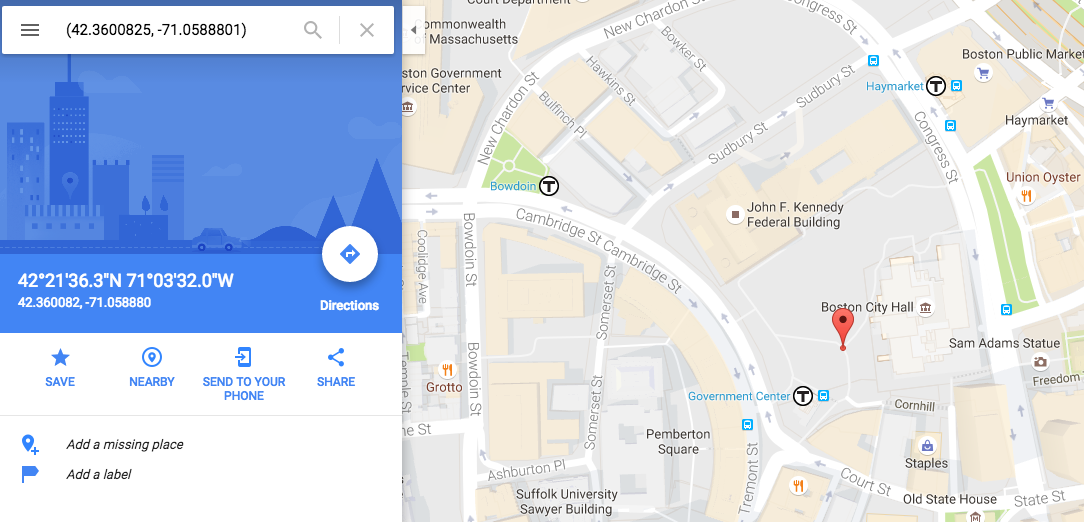
Checking that it works correctly for Boston:
Map it
I mapped the cities using Carto. The size of the bubbles represents the number of times that each city is mentioned in the text.